
Yesterday I wrote about fuzzing Suricata with AFL. Today I’m going to show another way. Since early in the project, we’ve shipped a perl based fuzzer called ‘wirefuzz’. The tool is very simple. It takes a list of pcaps, changes random bits in them using Wiresharks editcap and runs them through Suricata. Early in the project Will Metcalf, who wrote the tool, found a lot of issues with it.
Since it’s random based fuzzing, the fuzzing is quite shallow. It is still a great way of stressing the decoder layers of Suricata though, as we need to be able to process all junk input correctly.
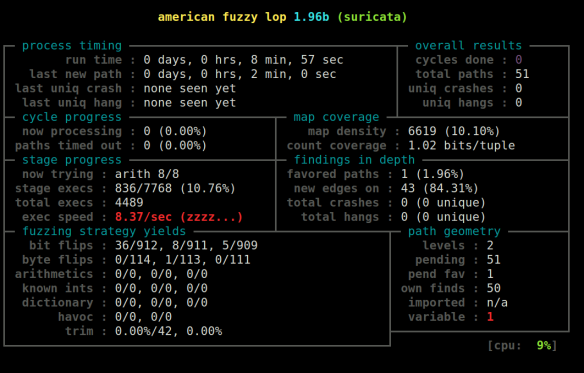
Lately we had an issue that I thought should have been found using fuzzing: #1653, and indeed, when I started fuzzing the code I found the issue within an hour. Pretty embarrassing.
Another reason to revisit is Address Sanitizer. It’s great because it’s so unforgiving. If it finds something it blows up. This is great for fuzzing. It’s recommended to use AFL with Asan as well. Wirefuzz does support a valgrind mode, but that is very slow. With Asan things are quite fast again, while doing much more thorough checking.
So I decided to spend some time on improving this tool so that I can add it to my CI set up.
Here is how to use it.
git clone https://github.com/inliniac/suricata -b dev-fuzz-v3.1 cd suricata git clone https://github.com/OISF/libhtp -b 0.5.x bash autogen.sh export CFLAGS="-fsanitize=address" ./configure --disable-shared --sysconfdir=/etc make mkdir fuzzer
# finally run the fuzzer
qa/wirefuzz.pl -r=/home/victor/pcaps/*/* -c=suricata.yaml -e=0.02 \
-p=src/suricata -l=fuzzer/ -S=rules/http-events.rules -N=1
What this command does is:
- run from the source dir, output into fuzzer/
- modify 2% of each pcap randomly while making sure the pcap itself stays valid (-e=0.02)
- use the rules file rules/http-events.rules exclusively (-S)
- use all the pcaps from /home/victor/pcaps/*/*
- return success if a single pass over the pcaps was done (-N=1)
One thing to keep in mind is that the script creates a copy of the pcap when randomizing it. This means that very large files may cause problems depending on your disk space.
I would encourage everyone to fuzz Suricata using your private pcap collections. Then report issues to me… pretty please? 🙂
*UPDATE 2/15*: the updated wirefuzz.pl is now part of the master branch.

You must be logged in to post a comment.